创建时间: 2024年11月4日 21:05
作者: 蜡笔大新
笔记类别: 强化学习
标签: Deep Reinforcement Learning, Policy Optimization, Q-Learning
状态: 完成
简介
Double DQN是深度强化学习中的一种改进算法,它解决了传统DQN(深度Q网络)中的过估计问题。传统DQN在某些情况下会高估Q值,导致学习效果不佳。Double DQN通过引入两个网络来缓解这个问题。
原理
- 使用两个结构相同但参数不同的神经网络:当前网络和目标网络。
- 当前网络用于选择动作,目标网络用于评估动作的价值。
- 这种分离减少了过度乐观估计的可能性。
步骤
- 使用当前网络,输入当前状态 $s_t$ 根据贪婪策略获得动作 $a_t$ 和对应的Q值 $Q_1$
- 当前状态 $s_t$ 根据选择的动作 $a_t$ 到达下一个状态 $s_{t+1}$
- 将下一个状态 $s_{t+1}$ 输入当前网络,选择最大Q值的动作 $a'$
- 将下一个状态 $s_{t+1}$ 输入目标网络,获得动作 $a'$ 对应的Q值 $Q_2$
- 将 $Q_1$ 和 $Q_2$ 计算TD-Error,通过梯度下降法更新当前网络
- 一段时间后,目标网络慢慢向当前网络靠拢
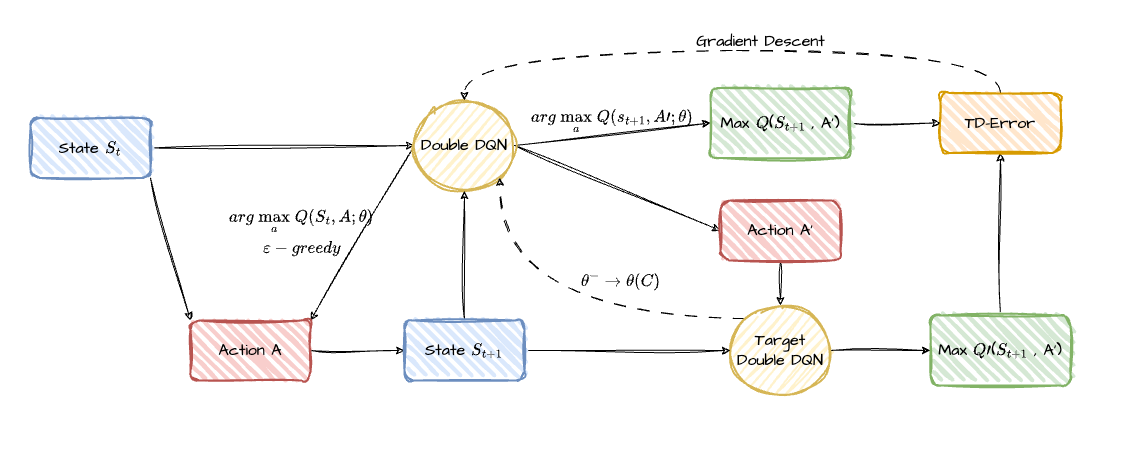
区别
在普通DQN中,当前网络和目标网络更像是两种并行的网络,目标网络只是当前网络参数较为稳定的版本,用于减缓目标漂移;而在Double DQN中,它们更像是互相合作的队友。当前网络负责提供动作,目标网络负责评估这个动作的质量,并反馈给当前网络。
当前网络
- 当前网络和普通DQN一样生成当前状态的不同动作的Q值,通过贪婪策略选择动作(大概率Q值最大,小概率随机探索)。
- 当前网络比普通DQN多了一步,将下一个状态输入进去,得到包含所有动作的Q值向量,选取下一个状态Q值最大的最佳动作。
目标网络
- 它不再直接通过贝尔曼公式计算当前状态的最大Q值,而是对当前网络选择的动作进行评估。
- 具体而言,将下一状态输入目标网络,使用目标网络生成的Q值中,与当前网络选择的动作对应的Q值作为 $Q{\prime}$ (目标Q值)。
- 通过计算TD误差(TD-Error)评估模型的质量,优化目标是最小化TD误差,并通过反向传播更新当前网络的参数。
优点
Double DQN的优点主要体现在以下几个方面:
- 更准确的Q值估计:通过分离动作选择和评估,有效减少了Q值的过估计问题。
- 提高学习稳定性:两个网络的协作机制使得学习过程更加稳定,减少了价值估计的波动。
- 更好的泛化能力:由于估计更准确,Double DQN在面对新的或未见过的状态时表现更好。
- 更快的收敛速度:相比传统DQN,Double DQN通常能更快地达到最优策略。
- 在复杂环境中表现出色:特别是在状态空间较大、动作选择复杂的环境中,Double DQN往往能取得更好的效果。
代码
环境
环境是倒立摆(Inverted Pendulum),在gym中对应的版本是Pendulum-v1。力矩大小是在[-2,2]范围内的连续值。由于DQN只能处理离散动作环境,因此我们无法直接用 DQN 来处理倒立摆环境,但倒立摆环境可以比较方便地验证 DQN 对Q值的过高估计:倒立摆环境下 Q值的最大估计应为0(倒立摆向上保持直立时能选取的最大值),Q值出现大于0的情况则说明出现了过高估计。为了能够应用DQN,我们采用离散化动作的技巧。例如,下面的代码将连续的动作空间离散为11个动作。动作 [0,1,2,...,9,10]分别代表力矩为[-2,-1.6, 1.2,..., 1.2, 1.6, 2]。
Double_DQN与DQN区别不大,主要改变的地方在于:
if self.dqn_type == 'DoubleDQN': # DQN与Double DQN的区别
max_action = self.q_net(next_states).max(1)[1].view(-1, 1)
max_next_q_values = self.target_q_net(next_states).gather(1, max_action)
else: # DQN的情况
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(-1, 1)总代码:
import random
import gym
import numpy as np
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import rl_utils
from tqdm import tqdm
class Qnet(torch.nn.Module):
""" 只有一层隐藏层的Q网络 """
def __init__(self, state_dim, hidden_dim, action_dim):
super(Qnet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x)
class DQN:
""" DQN算法,包括Double DQN """
def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma, epsilon, target_update, device,
dqn_type='VanillaDQN'):
self.action_dim = action_dim
self.q_net = Qnet(state_dim, hidden_dim, self.action_dim).to(device)
self.target_q_net = Qnet(state_dim, hidden_dim, self.action_dim).to(device)
self.optimizer = torch.optim.Adam(self.q_net.parameters(), lr=learning_rate)
self.gamma = gamma
self.epsilon = epsilon
self.target_update = target_update
self.count = 0
self.dqn_type = dqn_type
self.device = device
def take_action(self, state):
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim)
else:
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.q_net(state).argmax().item()
return action
def max_q_value(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
return self.q_net(state).max().item()
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)
q_values = self.q_net(states).gather(1, actions) # Q值
# 下个状态的最大Q值
if self.dqn_type == 'DoubleDQN': # DQN与Double DQN的区别
max_action = self.q_net(next_states).max(1)[1].view(-1, 1)
max_next_q_values = self.target_q_net(next_states).gather(1, max_action)
else: # DQN的情况
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(-1, 1)
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones) # TD误差目标
dqn_loss = torch.mean(F.mse_loss(q_values, q_targets)) # 均方误差损失函数
self.optimizer.zero_grad() # PyTorch中默认梯度会累积,这里需要显式将梯度置为0
dqn_loss.backward() # 反向传播更新参数
self.optimizer.step()
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(self.q_net.state_dict()) # 更新目标网络
self.count += 1
lr = 1e-2
num_episodes = 200
hidden_dim = 128
gamma = 0.98
epsilon = 0.01
target_update = 50
buffer_size = 5000
minimal_size = 1000
batch_size = 64
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
env_name = 'Pendulum-v1'
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = 11 # 将连续动作分成11个离散动作
def dis_to_con(discrete_action, env, action_dim): # 离散动作转回连续的函数
action_lowbound = env.action_space.low[0] # 连续动作的最小值
action_upbound = env.action_space.high[0] # 连续动作的最大值
return action_lowbound + (discrete_action / (action_dim - 1)) * (action_upbound - action_lowbound)
def train_DQN(agent, env, num_episodes, replay_buffer, minimal_size, batch_size):
return_list = []
max_q_value_list = []
max_q_value = 0
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
max_q_value = agent.max_q_value(state) * 0.005 + max_q_value * 0.995 # 平滑处理
max_q_value_list.append(max_q_value) # 保存每个状态的最大Q值
action_continuous = dis_to_con(action, env, agent.action_dim)
next_state, reward, done, _ = env.step([action_continuous])
replay_buffer.add(state, action, reward, next_state, done)
state = next_state
episode_return += reward
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
transition_dict = {
'states': b_s,
'actions': b_a,
'next_states': b_ns,
'rewards': b_r,
'dones': b_d
}
agent.update(transition_dict)
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode': '%d' % (num_episodes / 10 * i + i_episode + 1),
'return': '%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
return return_list, max_q_value_list
random.seed(0)
np.random.seed(0)
env.seed(0)
torch.manual_seed(0)
replay_buffer = rl_utils.ReplayBuffer(buffer_size)
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon, target_update, device)
return_list, max_q_value_list = train_DQN(agent, env, num_episodes, replay_buffer, minimal_size, batch_size)
episodes_list = list(range(len(return_list)))
mv_return = rl_utils.moving_average(return_list, 5)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN on {}'.format(env_name))
plt.show()
frames_list = list(range(len(max_q_value_list)))
plt.plot(frames_list, max_q_value_list)
plt.axhline(0, c='orange', ls='--')
plt.axhline(10, c='red', ls='--')
plt.xlabel('Frames')
plt.ylabel('Q value')
plt.title('DQN on {}'.format(env_name))
plt.show()
random.seed(0)
np.random.seed(0)
env.seed(0)
torch.manual_seed(0)
replay_buffer = rl_utils.ReplayBuffer(buffer_size)
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon, target_update, device, 'DoubleDQN')
return_list, max_q_value_list = train_DQN(agent, env, num_episodes, replay_buffer, minimal_size, batch_size)
episodes_list = list(range(len(return_list)))
mv_return = rl_utils.moving_average(return_list, 5)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('Double DQN on {}'.format(env_name))
plt.show()
frames_list = list(range(len(max_q_value_list)))
plt.plot(frames_list, max_q_value_list)
plt.axhline(0, c='orange', ls='--')
plt.axhline(10, c='red', ls='--')
plt.xlabel('Frames')
plt.ylabel('Q value')
plt.title('Double DQN on {}'.format(env_name))
plt.show()
100轮结果对比
总体奖励回报
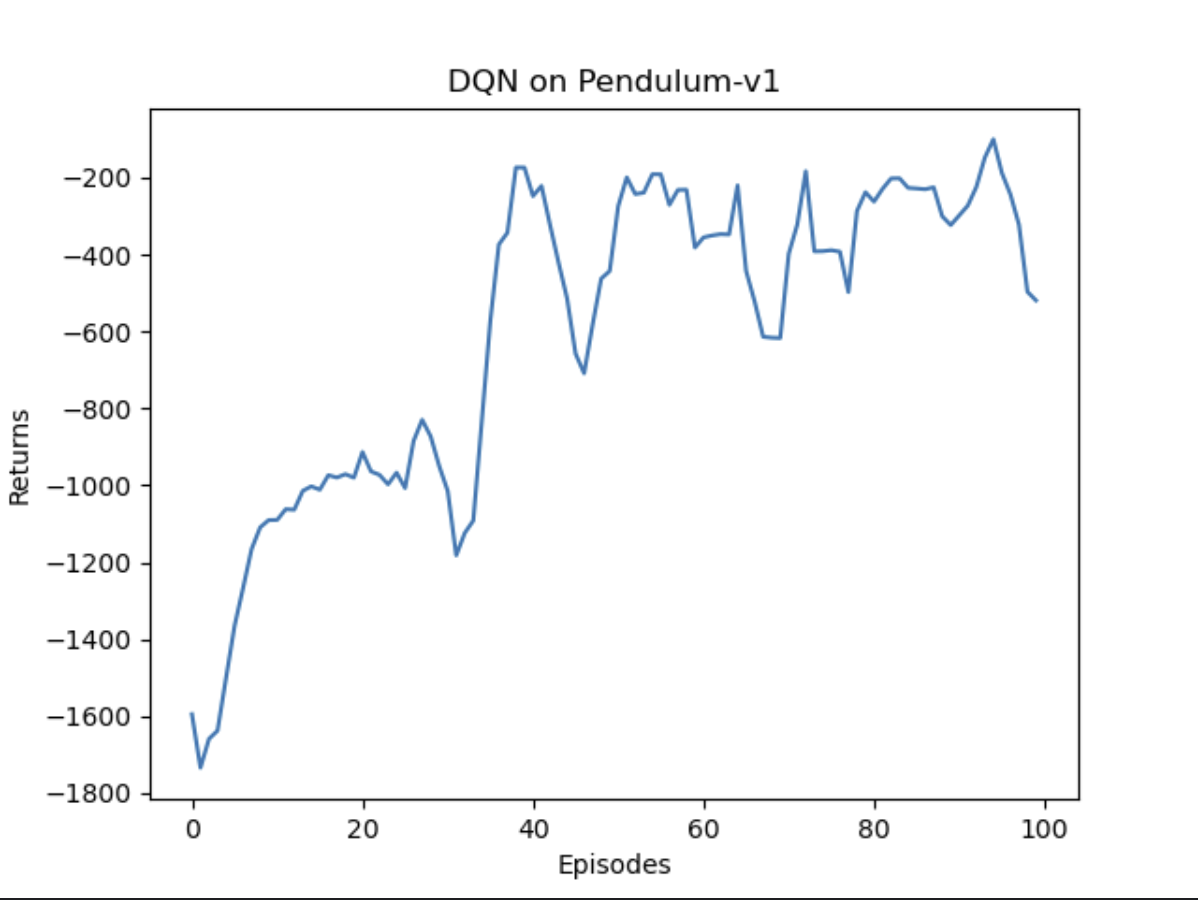
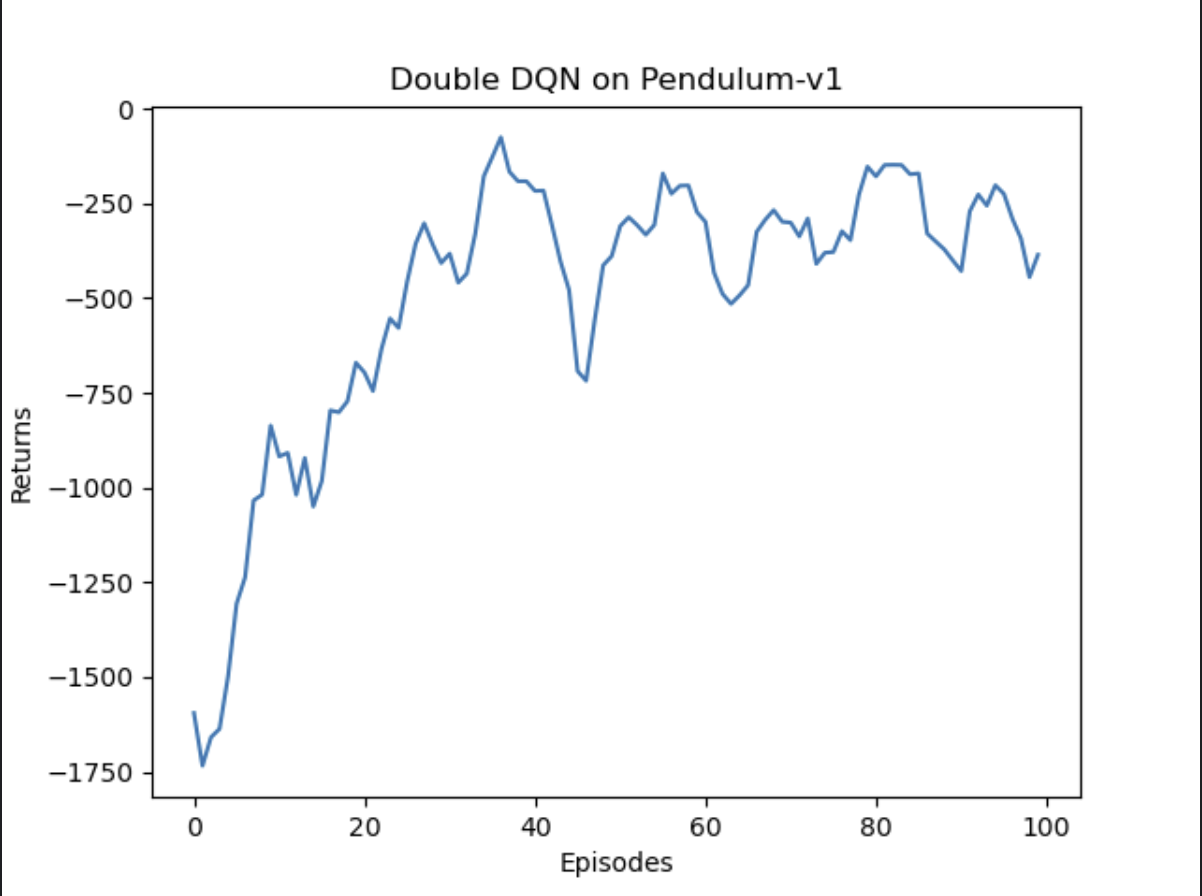
预估Q值
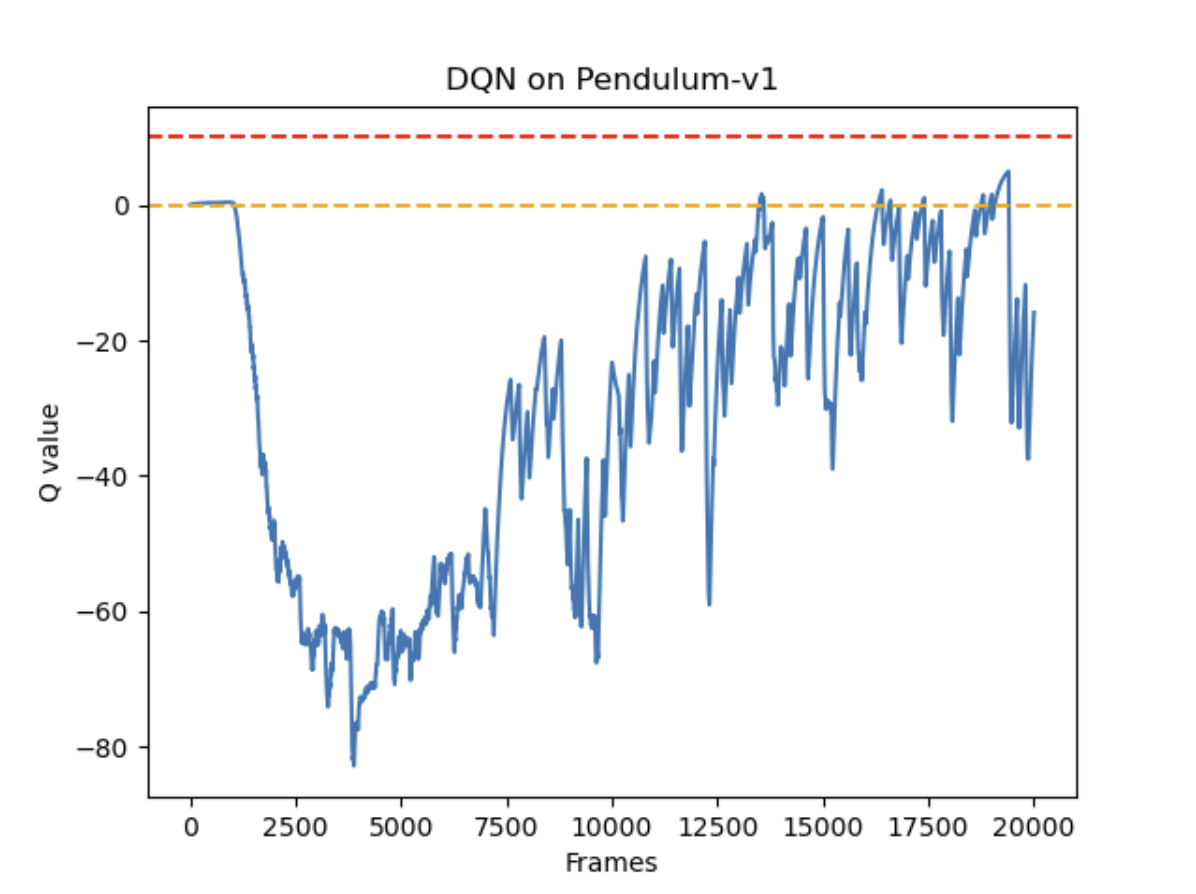
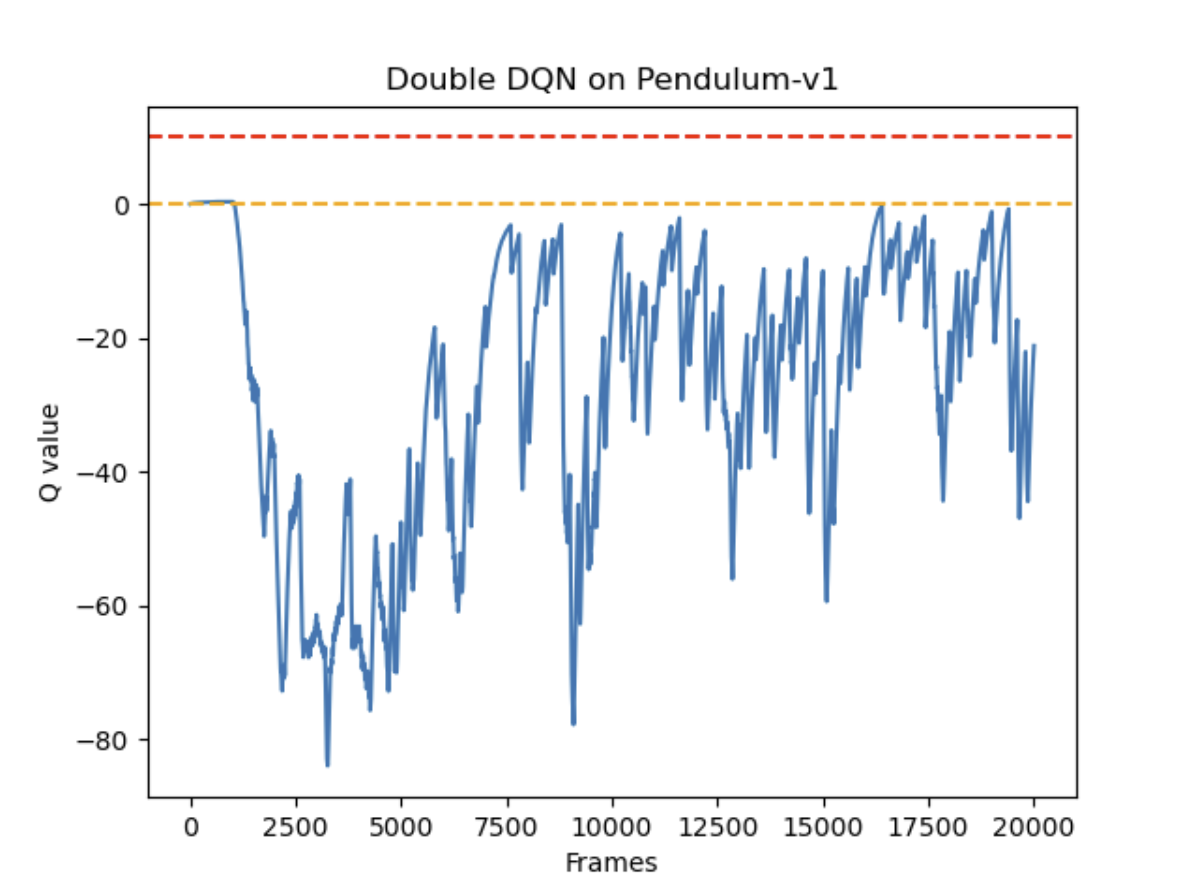
总体奖励回报上,DQN和Double DQN都在训练中提升了表现,总体奖励相差不大。而在预估Q值时,DQN明显表现出了过度估计Q值(理论上不会出现正的Q值),Double DQN能够更准确的估计Q值。
1000轮结果对比
总体奖励回报
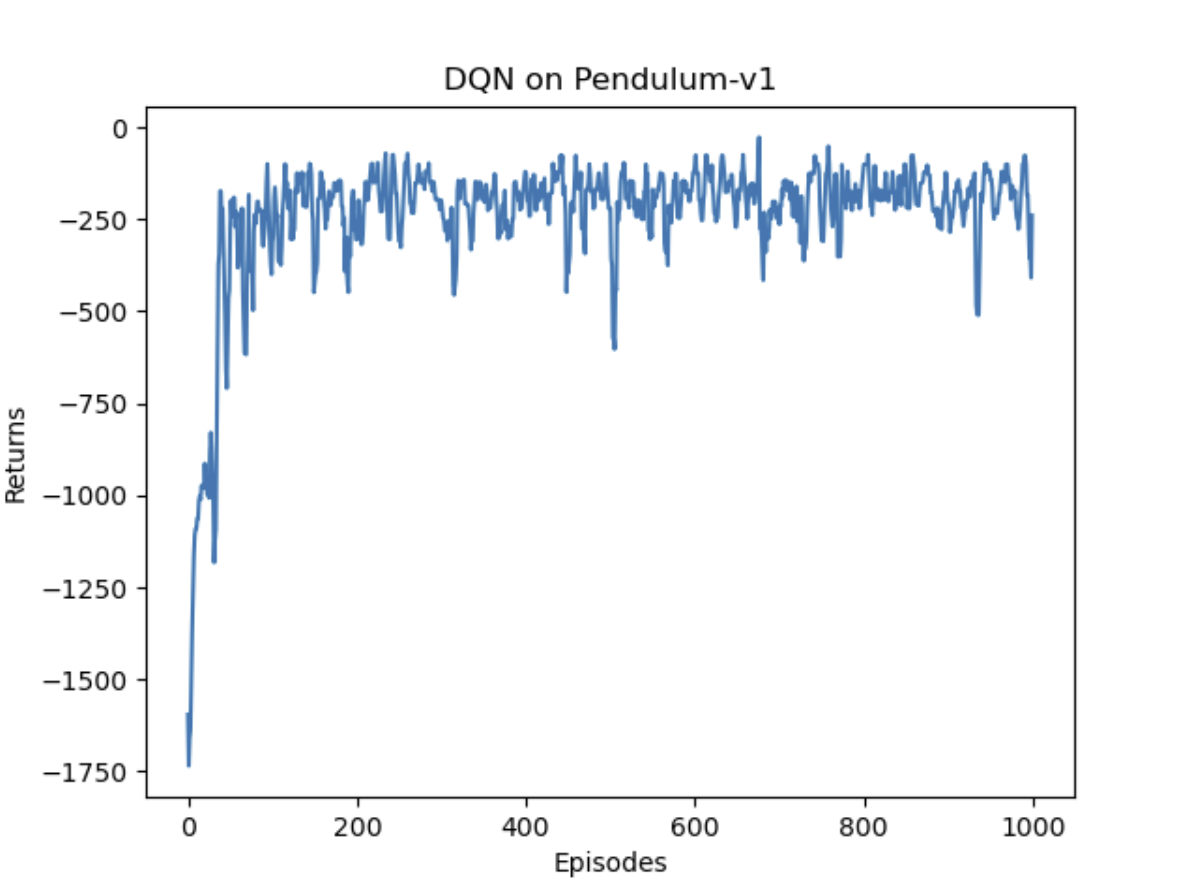
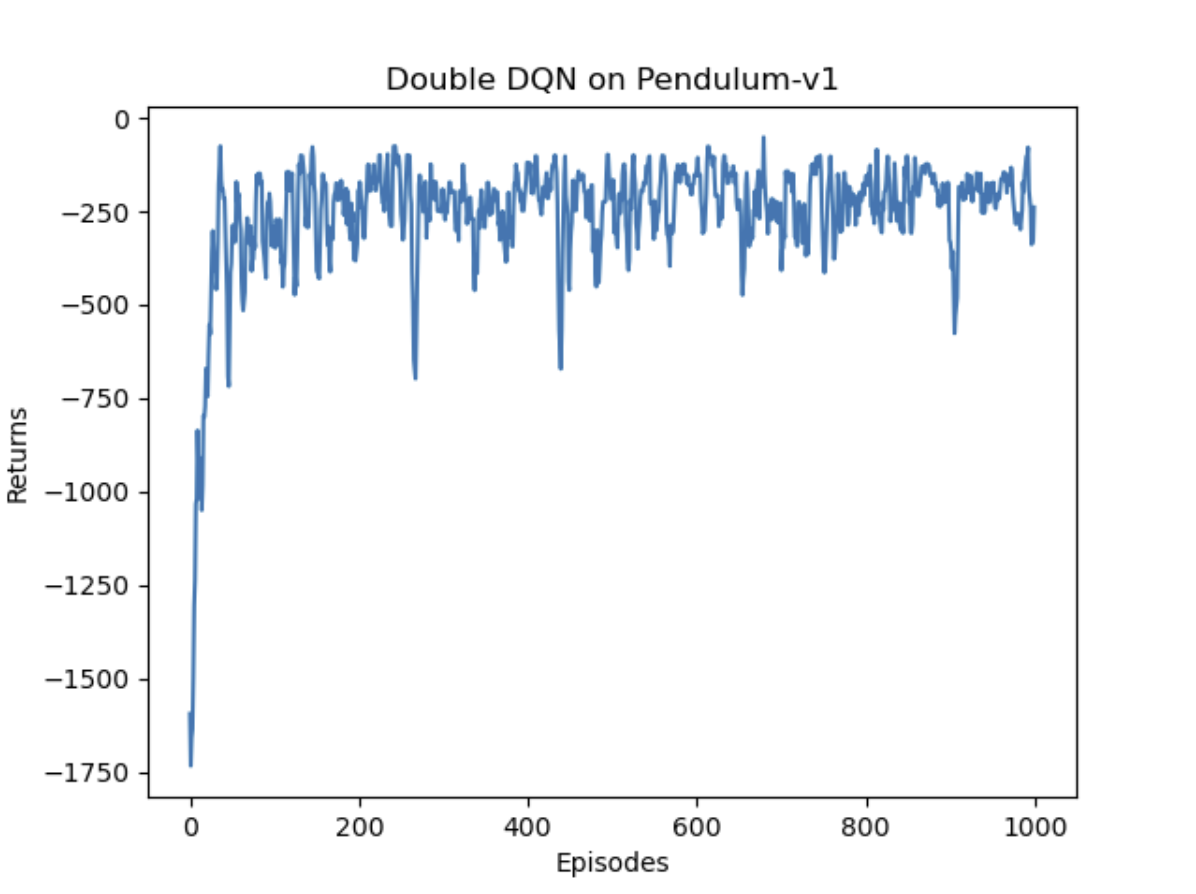
预估Q值
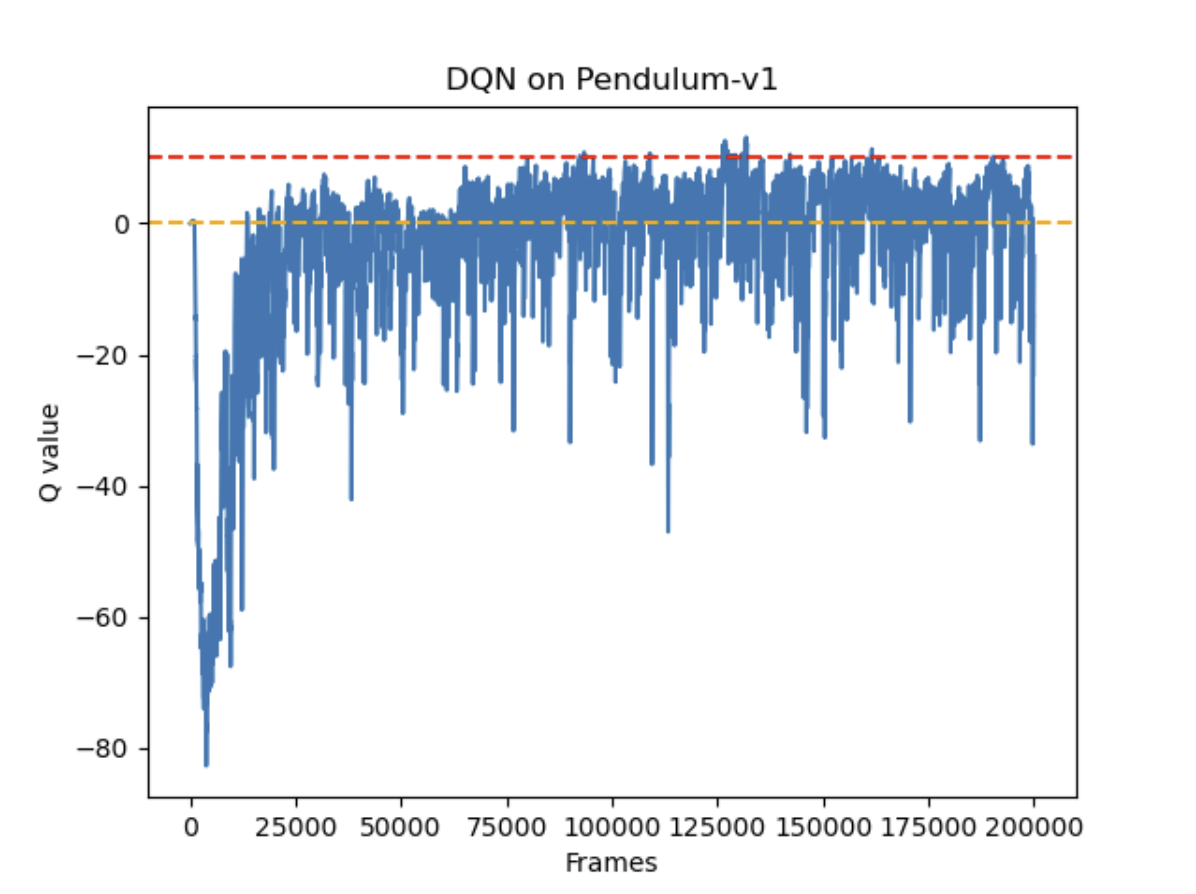
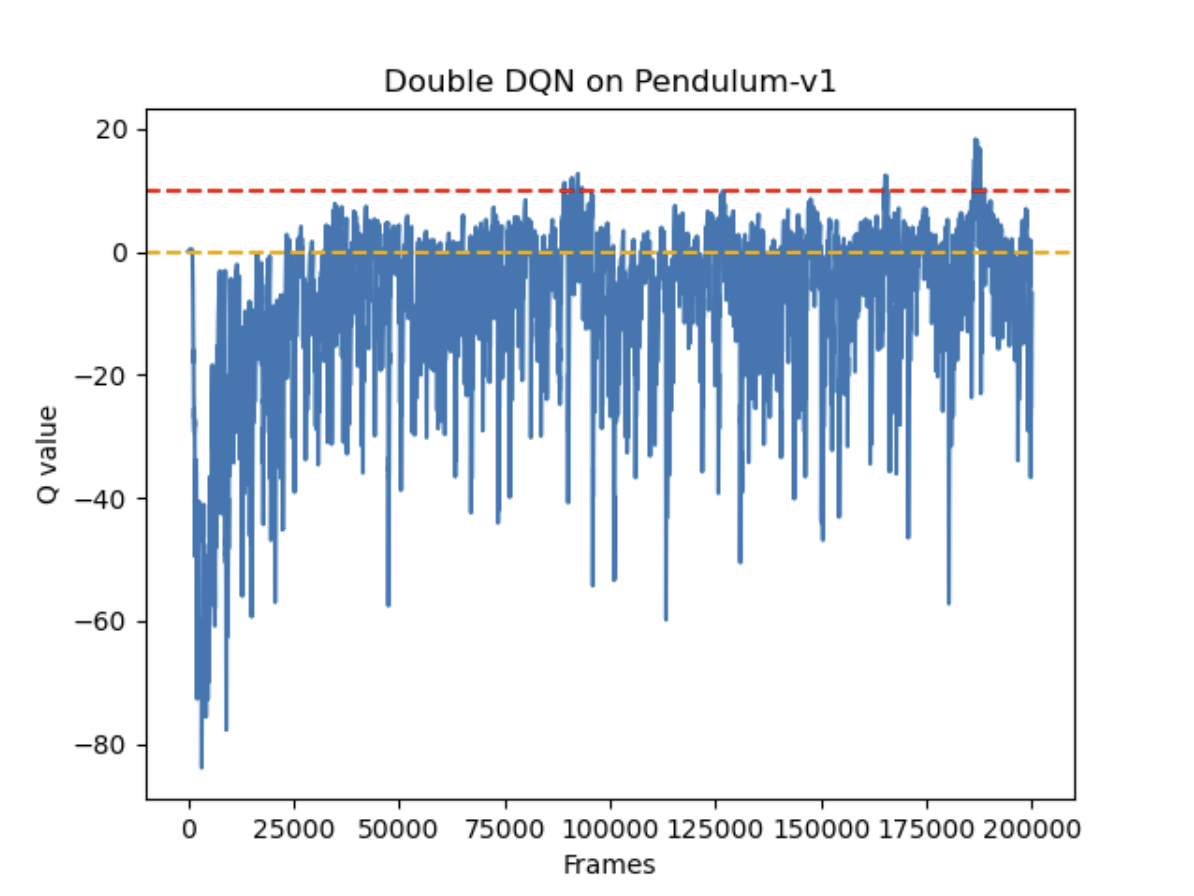
实验结果显示,在这个游戏中,两种网络获得的奖励基本持平,但DQN表现更稳定。在Q值预估方面,虽然两种网络都出现了大于0的情况,DQN明显更频繁地过高估计Q值,而Double DQN在一定程度上缓解了这个问题。值得注意的是,为了使两种DQN能够运行,原本的连续动作被改为离散动作,这可能对实验结果产生了一定影响。
