创建时间: 2024年10月24日 13:53
作者: 蜡笔大新
笔记类别: 强化学习
标签: Deep Reinforcement Learning, Experience Replay, Q-Learning
状态: 完成
传统Q-Learning的一些问题
在Q-Learning中,需要反复更新Q-table,最终通过贪心算法根据Q表选取相应的动作。而这通常会带来一些问题,比如动作和状态维度过高之后,Q-table的维度也会非常高,带来计算和存储的巨大压力。
DQN介绍
DQN(Deep Q-Network)是一种结合了 深度学习 和 Q-Learning 的强化学习算法,它通过深度神经网络来近似 Q 值函数,从而能够处理高维状态空间问题。

优点
DQN 使用一个 深度神经网络(DNN) 来代替传统 Q-Learning 中的 Q 表格,将状态作为输入,通过神经网络输出对应每个动作的 Q 值。这使得 DQN 能够处理复杂和高维的状态空间,比如在图像、视频帧等环境下的强化学习问题。
传统的Q-Learning很适合格子游戏。因为格子游戏中的每一个格子就是一个状态,但在现实生活中,很多状态并不是离散而是连续的。通过函数的形式就可以很好的解决连续的状态问题,比如驾驶的方向等。
训练
经验回放
DQN 引入了一个非常重要的技术:经验回放,它的作用是打破样本之间的时间相关性,并使得神经网络的训练更加稳定。
在训练过程中,DQN 会从这个 经验池 中随机抽取样本来训练神经网络,从而减少数据之间的相关性,提升训练稳定性。
模型
DQN引入了目标网络(Target网络)与主体网络,它们是互相隔离的。目标网络的参数每隔一段时间才会从当前网络复制,而不是每步都更新。这样设计的目标主要是为了网络稳定,避免发散。或者以操作系统举例,主网络就是Beta测试版,Target网络就是Latest稳定版。稳定版会每隔一段时间或条件向测试版偏移。
损失函数
DQN 的训练目标是通过最小化当前 Q 值和目标 Q 值之间的误差来优化模型。常用的误差函数是 均方误差(MSE, Mean Squared Error):
$$ L(\theta)= [y-Q(s,a)]^2 $$
其中:
- $y=Q(s_t, a_t) + \alpha \left[ r_t + \gamma \max_{a'} Q(s_{t+1}, a') - Q(s_t, a_t) \right]$,即贝尔曼公式,由目标DQN计算。
- $Q(s,a)$:当前 Q 值,由 当前DQN 网络预测。
仍然分两个网络来讲:
- 当前DQN:输出 $Q(s,a)$
- 目标DQN:选取目标网络下下一个状态Q最大的动作,将其收益、Q值等代入贝尔曼公式输出y值。
输入输出
DQN接受当前状态,并且能输出一个包含所有动作Q值的向量,每个动作的顺序在定义网络结构的时候就已经确定了,并在整个训练和使用过程中保持不变。神经网络的输出层有固定数量的节点,每个节点对应一个特定的动作。
例如,在CartPole-v0环境中,动作空间只有两个动作(向左推和向右推)。DQN的输出层就会有两个节点,可能表示为:
第一个节点(索引0):向左推的Q值
第二个节点(索引1):向右推的Q值
动作选择
当输入状态后,网络会输出包含所有动作Q值的向量。选择动作主要有两种策略:
- 贪婪策略(Greedy Policy):在大多数情况下,DQN会选择Q值最高的动作。这就是所谓的利用(exploitation)。
- ε-贪婪策略(ε-greedy Policy):为了平衡探索和利用,DQN通常会采用ε-贪婪策略。具体来说:
- 以ε的概率随机选择一个动作(探索)
- 以1-ε的概率选择Q值最高的动作(利用)
代码
CartPole-v0
CartPole-v0 是OpenAI Gym中的一个经典控制问题环境。在这个环境中:
- 一个杆子通过一个非驱动关节连接到一个可以左右移动的小车上。
- 系统开始时杆子是垂直的,目标是通过左右移动小车来保持杆子直立。
- 每个时间步,agent可以选择向左或向右推车。
- 每次成功保持杆子直立的时间步骤都会获得+1的奖励。
- 当杆子倾斜超过15度,或者小车移动超出中心2.4个单位,或者回合持续超过200个时间步时,回合结束。
在游戏中每坚持一帧,智能体能获得分数为 1 的奖励,坚持时间越长,则最后的分数越高,坚持 200 帧即可获得最高的分数。(也就是说,奖励和到达200即可结束游戏)

import random
import gym
import numpy as np
import collections
from tqdm import tqdm
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
import rl_utils
class ReplayBuffer:
''' 经验回放池 '''
def __init__(self, capacity):
self.buffer = collections.deque(maxlen=capacity) # 队列,先进先出
def add(self, state, action, reward, next_state, done): # 将数据加入buffer
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size): # 从buffer中采样数据,数量为batch_size
transitions = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = zip(*transitions)
return np.array(state), action, reward, np.array(next_state), done
def size(self): # 目前buffer中数据的数量
return len(self.buffer)
class Qnet(torch.nn.Module):
''' 只有一层隐藏层的Q网络 '''
def __init__(self, state_dim, hidden_dim, action_dim):
super(Qnet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x)) # 隐藏层使用ReLU激活函数
return self.fc2(x)
class DQN:
''' DQN算法 '''
def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma,
epsilon, target_update, device):
self.action_dim = action_dim
self.q_net = Qnet(state_dim, hidden_dim,
self.action_dim).to(device) # Q网络
# 目标网络
self.target_q_net = Qnet(state_dim, hidden_dim,
self.action_dim).to(device)
# 使用Adam优化器
self.optimizer = torch.optim.Adam(self.q_net.parameters(),
lr=learning_rate)
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # epsilon-贪婪策略
self.target_update = target_update # 目标网络更新频率
self.count = 0 # 计数器,记录更新次数
self.device = device
def take_action(self, state): # epsilon-贪婪策略采取动作
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim)
else:
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.q_net(state).argmax().item()
return action
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
q_values = self.q_net(states).gather(1, actions) # Q值
# 下个状态的最大Q值
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(
-1, 1)
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones
) # TD误差目标
dqn_loss = torch.mean(F.mse_loss(q_values, q_targets)) # 均方误差损失函数
self.optimizer.zero_grad() # PyTorch中默认梯度会累积,这里需要显式将梯度置为0
dqn_loss.backward() # 反向传播更新参数
self.optimizer.step()
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(
self.q_net.state_dict()) # 更新目标网络
self.count += 1
lr = 2e-3
num_episodes = 500
hidden_dim = 128
gamma = 0.98
epsilon = 0.01
target_update = 10
buffer_size = 10000
minimal_size = 500
batch_size = 64
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
env_name = 'CartPole-v0'
env = gym.make(env_name)
random.seed(0)
np.random.seed(0)
env.seed(0)
torch.manual_seed(0)
replay_buffer = ReplayBuffer(buffer_size)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,
target_update, device)
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, _ = env.step(action)
replay_buffer.add(state, action, reward, next_state, done)
state = next_state
episode_return += reward
# 当buffer数据的数量超过一定值后,才进行Q网络训练
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
transition_dict = {
'states': b_s,
'actions': b_a,
'next_states': b_ns,
'rewards': b_r,
'dones': b_d
}
agent.update(transition_dict)
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN on {}'.format(env_name))
plt.show()
mv_return = rl_utils.moving_average(return_list, 9)
plt.plot(episodes_list, mv_return)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN on {}'.format(env_name))
plt.show()结果

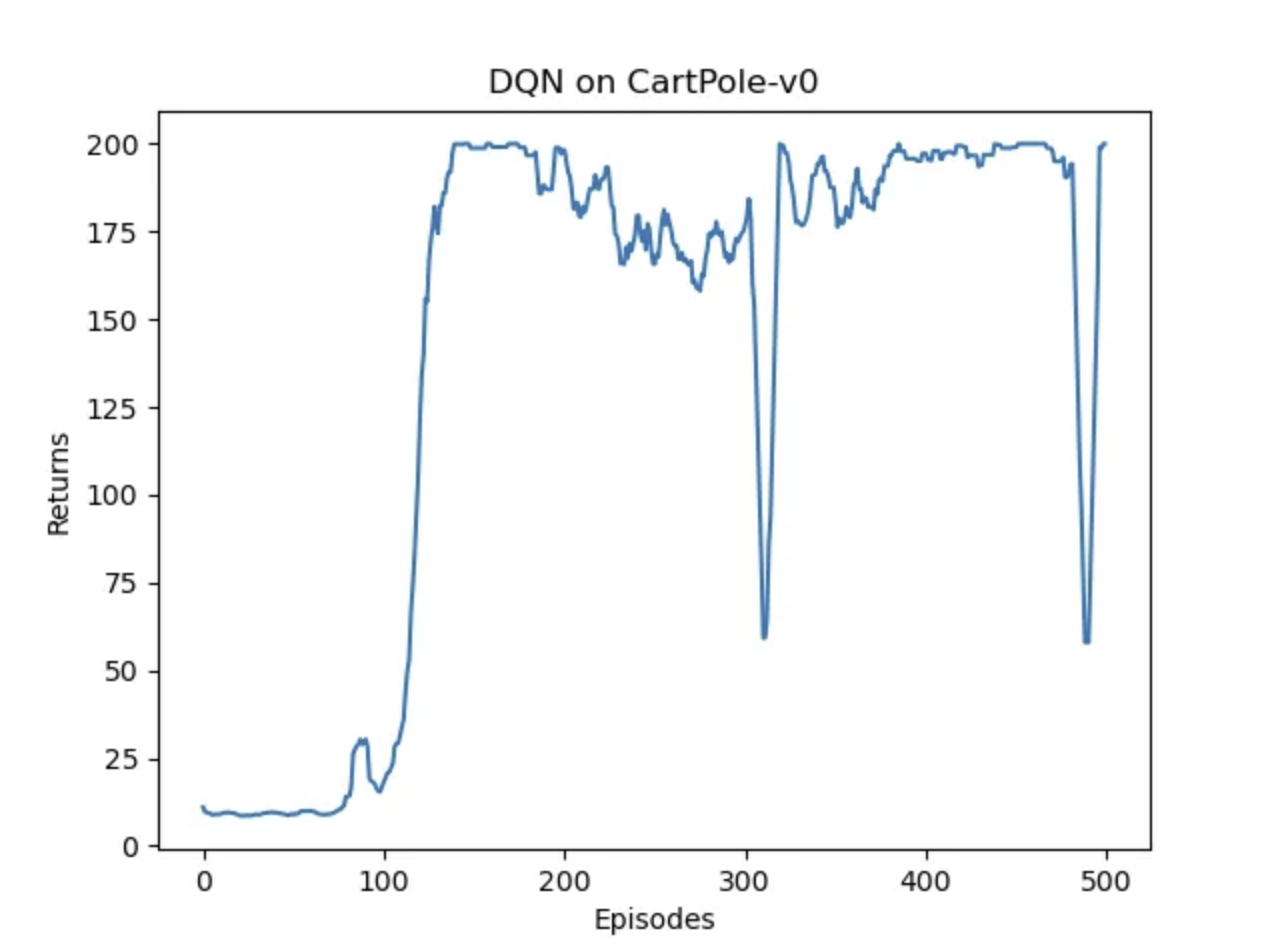
总体而言,奖励能够到达200,说明网络拥有不错的性能,但是还是有些不太稳定,产生了震荡。