介绍
根据PyTorch在2022年推出的文章来看,M系列芯片的mac已经可以使用GPU加速训练。
pytorch
使用起来也非常方便,和cuda类似:
torch.backends.mps.is_available()torch.device("mps")实验
使用PyTorch官方的MNIST例子,即手写数字识别。对比了一下不同系统下CPU和GPU加速的对比效果。实验均采用Batch=64,Epoch=5的参数。
实验一(Mac M4)
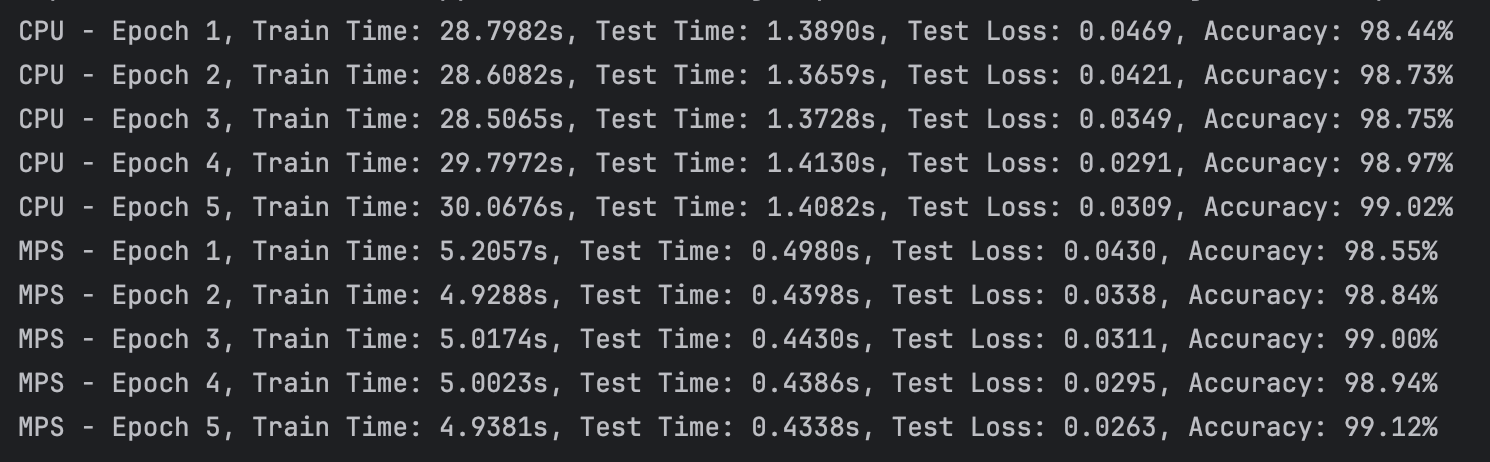
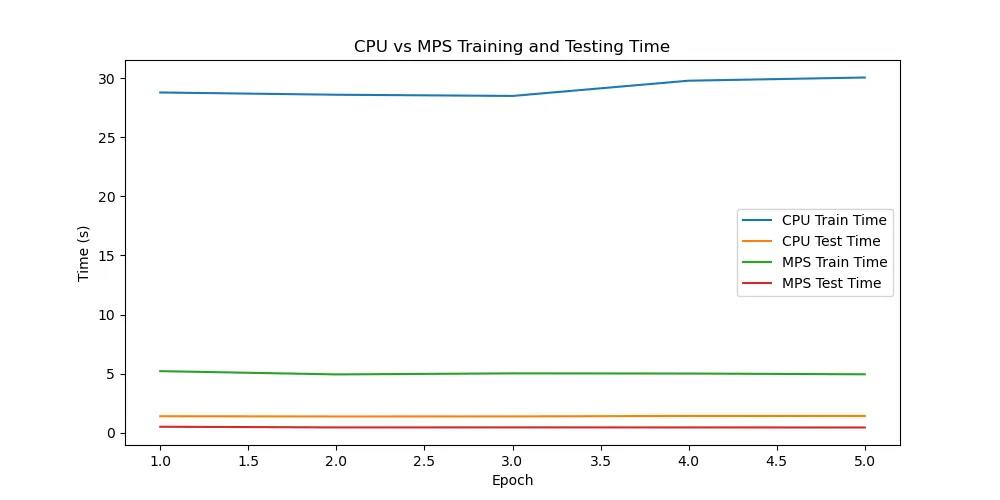
芯片:M4
实验二(Mac M1)
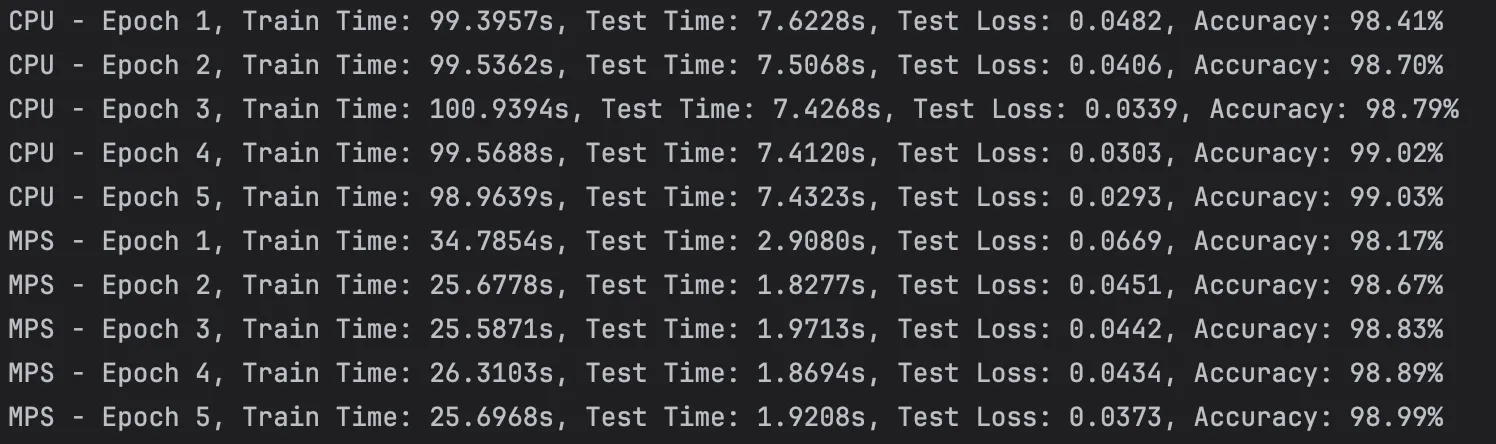
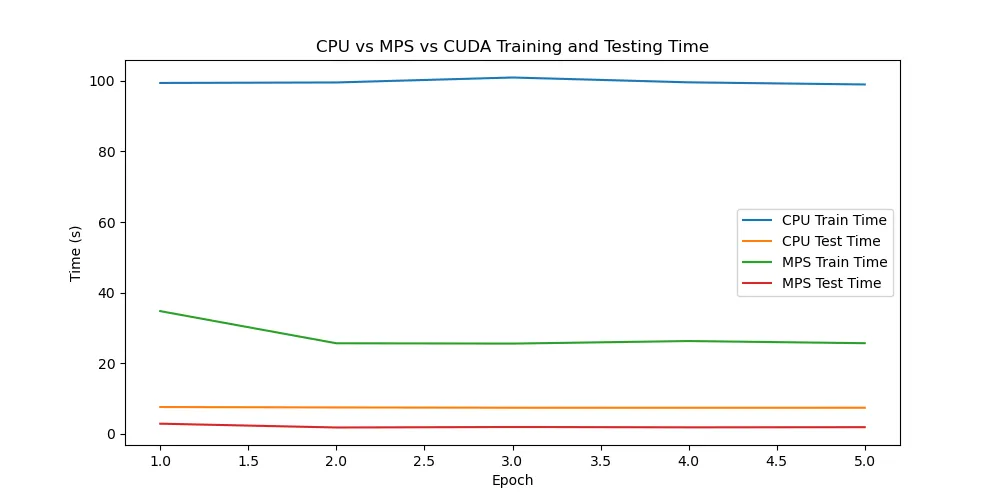
芯片:M1
实验三(Win)
CPU:AMD R7-5800H
GPU:RTX3060 Laptop 130w
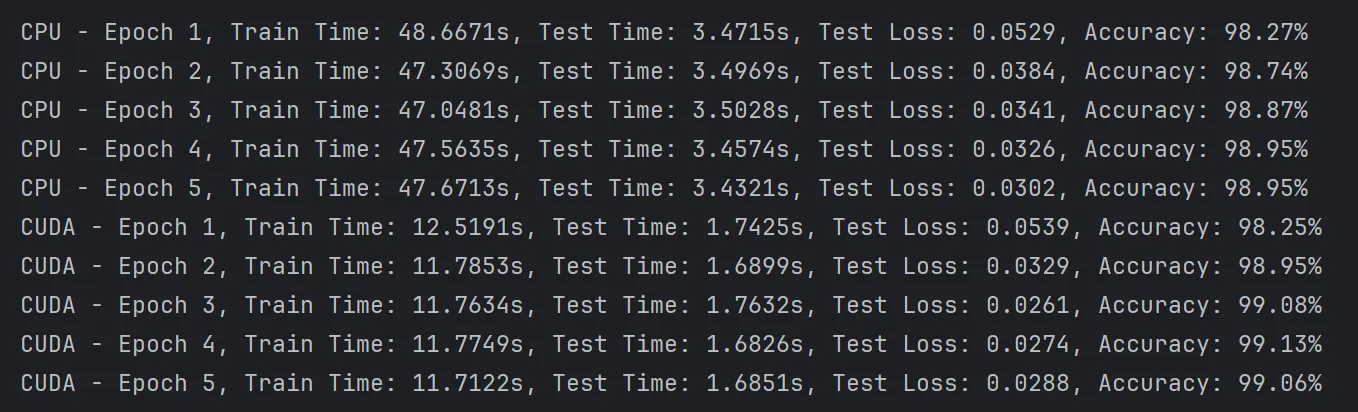
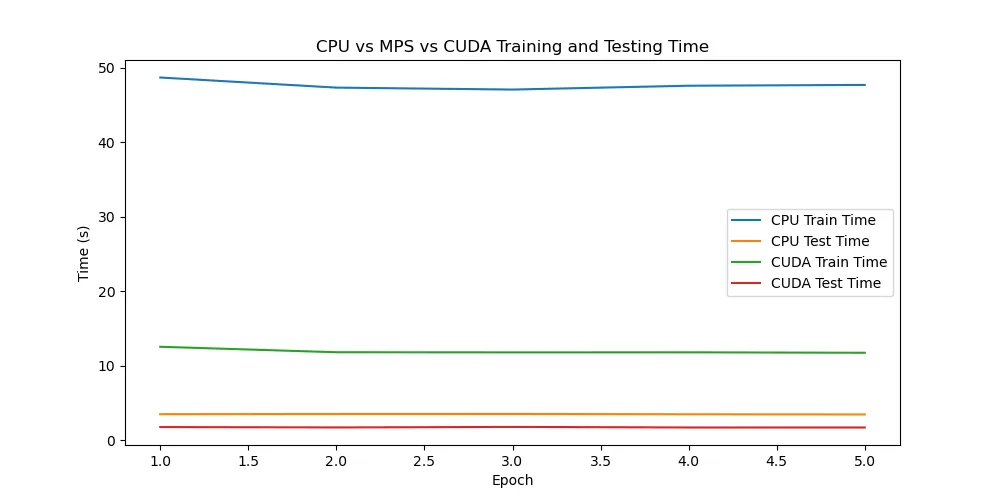
结论
通过实验可以看出,苹果的M4芯片相较于M1芯片进步异常明显,使用GPU(mps)加速可以非常显著的提升训练和测试的速度。而相较于笔记本的3060显卡,mps加速竟然比cuda加速还要快。但是,由于是PyTorch官方推出的案例,难免会进行特殊优化。在强化学习的学习中,并没有发现mps比cpu快很多,甚至还不如cpu正常跑,可能与批次等参数的设置也有关,有待后续继续实验。
代码
import argparse
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
import matplotlib.pyplot as plt
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
return test_loss, accuracy
def measure_time(device_name, device, train_loader, test_loader, args):
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
train_times, test_times = [], []
for epoch in range(1, args.epochs + 1):
# Training time
start_train = time.time()
train(model, device, train_loader, optimizer, epoch)
end_train = time.time()
train_times.append(end_train - start_train)
# Testing time
start_test = time.time()
test_loss, accuracy = test(model, device, test_loader)
end_test = time.time()
test_times.append(end_test - start_test)
scheduler.step()
print(f"{device_name} - Epoch {epoch}, Train Time: {train_times[-1]:.4f}s, Test Time: {test_times[-1]:.4f}s, "
f"Test Loss: {test_loss:.4f}, Accuracy: {accuracy:.2f}%")
return train_times, test_times
def plot_times(cpu_times, mps_times, cuda_times, args):
epochs = range(1, args.epochs + 1)
plt.figure(figsize=(10, 5))
# Plot CPU, MPS (if available), and CUDA (if available) times
plt.plot(epochs, cpu_times[0], label='CPU Train Time')
plt.plot(epochs, cpu_times[1], label='CPU Test Time')
if mps_times:
plt.plot(epochs, mps_times[0], label='MPS Train Time')
plt.plot(epochs, mps_times[1], label='MPS Test Time')
if cuda_times:
plt.plot(epochs, cuda_times[0], label='CUDA Train Time')
plt.plot(epochs, cuda_times[1], label='CUDA Test Time')
plt.xlabel('Epoch')
plt.ylabel('Time (s)')
plt.title('CPU vs MPS vs CUDA Training and Testing Time')
plt.legend()
plt.show()
def main():
parser = argparse.ArgumentParser(description='PyTorch MNIST Example with CPU, MPS, and CUDA Comparison')
parser.add_argument('--batch-size', type=int, default=64)
parser.add_argument('--test-batch-size', type=int, default=1000)
parser.add_argument('--epochs', type=int, default=5)
parser.add_argument('--lr', type=float, default=1.0)
parser.add_argument('--gamma', type=float, default=0.7)
args = parser.parse_args()
torch.manual_seed(1)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('./data', train=True, download=True, transform=transform)
dataset2 = datasets.MNIST('./data', train=False, transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1, batch_size=args.batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset2, batch_size=args.test_batch_size, shuffle=False)
# Measure CPU time
cpu_times = measure_time("CPU", torch.device("cpu"), train_loader, test_loader, args)
# Measure MPS time if available
mps_times = None
if torch.backends.mps.is_available():
mps_times = measure_time("MPS", torch.device("mps"), train_loader, test_loader, args)
# Measure CUDA time if available
cuda_times = None
if torch.cuda.is_available():
cuda_times = measure_time("CUDA", torch.device("cuda"), train_loader, test_loader, args)
# Plot results
plot_times(cpu_times, mps_times, cuda_times, args)
if __name__ == '__main__':
main()